Objet : Analyse et Comparaison avec et sans DMA,
Pour un projet particulier, j'ai eu besoin d'utiliser un écran écran couleur LCD 320x240 à base de driver ILI9341 Driver sur STM32F401
Pour tester et démarrer au plus vite, J'ai téléchargé une librairie sur STM32F4/29 Discovery.com
L'auteur et admin de ce site développe un grand nombre de librairies. Il est très actif et répond rapidement à toutes les questions qu'on lui pose.
Donc j'ai fait un projet simple pour tester sur ma carte Nucleo STM32F401RE.
Le LCD est utilisé en mode SPI car c'est ce mode qui est le plus utilisé sur les shield et carte qu'on trouve facilement sur internet.
Lorsque que j'ai programmé ma carte avec la "Librairie Discovery", ça a tout de suite fonctionné (une petite configuration suffit, la librairie est très bien écrite et est simple à utiliser).
Mais l'affichage est très lent. Ce n'est pas dû au code de l'auteur, il a fait un sacré boulot, mais c'est lié au principe de la méthode utilisée.
Electrodacus, un utilisateur de la librairie et un follower du site, a mis une vidéo sur youtube qui montre l'amélioration de vitesse de la librairie initiale, en appliquant le DMA.
Ma vidéo ci dessous compare les 3 méthodes :
- A/ La librairie d'origine, sans modification
- B/ La librairie d'origine, en appliquant la technique de pagination
- C/ La librairie modifiée avec pagination et DMA
Ma vidéo synchronise les 3 videos au même moment pour comparer la vitesse pendant 2 cycles de comptage.
1 - Petite discussion à propos de la vitesse du SPI
stm32f4-discovery.com a écrit un bon article sur le SPI et la configuration de la vitesse, en fonction du canal choisi et de la configuration de l'horloge. Veuillez lire cet article avant de continuer, si vous n'êtes pas familiarisé avec le bus SPI et la configuration du STM32.
Dans mon cas, j'ai vérifié la fréquence de l'horloge du SPI à l'oscilloscope : la période est de 1/21MHz environ = 48ns par période d'horloge. ça signifie que pour transmettre un octet il faut 8x48ns = 380ns.
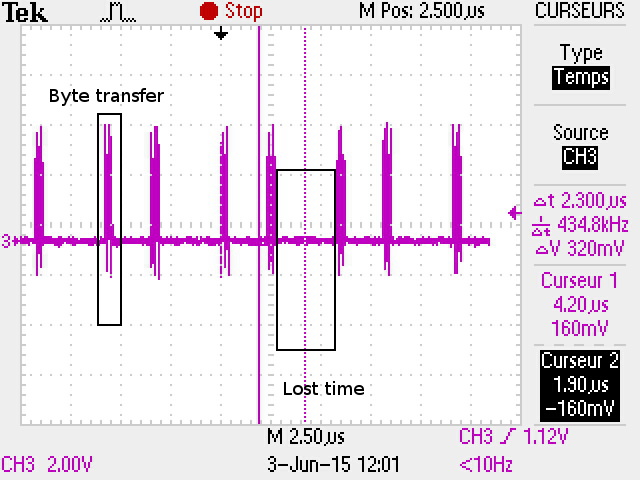
Pour 1 octet, le SPI est à vitesse maxi mais nous perdons du temps entre chaque octet: le code a besoin d’exécuter des fonctions, le transfert de données ou des interruptions. Jusqu'à ce que la valeur soit stockée dans le registre de donnée du SPI (SPI->DR),le temps n'est pas certain.
La meilleure solution de transfert est de ne pas perdre de temps entre les octets. Avec du code et un algorithme, c'est impossible, parce que vous êtes dépendant des lignes de code exécutées et du boulot que doit faire le microcontrôleur.
Pour optimiser le transfert, on utilise le DMA. Le DMA est utilisé pour transférer des données entre la mémoire et le périphérique (et plus généralement entre mémoire/périphérique vers mémoire/périphérique).
Dans notre cas, Le DMA peut transférer les données de la mémoire vers le registre SPI->DR automatiquement. Quand la donnée a fini d'être transférée sur le SPI, le DMA place une nouvelle donnée dans le registre DR et lance le transfert, et ainsi de suite jusqu'à ce que le compteur soit égale à 0.
De plus, le driver ILI9341 a 2 modes de transfert de données : commande et données. A cause de cette différence, le DMA ne peut être utilisé que pour le mode données et pas pour la commande.
- Le signal D/C (WRX) doit être mis à 0 avant de transférer une commande, et seulement pour 1 octet
- Le signal D/C (WRX) doit être mis à 1 pour le transfert des données et multiple données
Les commandes ne sont codées que sur 1 octet, donc le DMA n'est pas necessaire.
Le DMA doit être utilisé pour envoyer plusieurs données. Habituellement, quand on dessine quelque chose sur l'écran, on envoie plusieurs pixels. Donc on peut optimiser le taux de transfert.
2- Librairie d'origine sans modification
La technique utilisée par la librairie est basé sur des fonctions élémentaires :
- DrawPixel : Cette fonction place le curseur à une position spécifique et envoie la valeur du pixel
- DrawLine : Cette fonction dessine une ligne avec DrawPixel.
- DrawRectangle :utilise DrawLine
- DrawFilledRectangle : utilise DrawLine aussi
Il y a aussi d'autres fonctions comme putc et puts qui permettent d’écrire une chaîne et des caractères sur l’écran.
Cette methode de tracé pose plusieurs problèmes de vitesse :
- A chaque fois qu'on veut dessiner un pixel, on envoie la position : Pour envoyer la position on a besoin de 10 octets+ 1 octet pour la commande d'accès à la GRAM et 2 octets pour la couleur.
- Pour une ligne on utilise DrawPixel, donc pour chaque pixel on affecte la position et on envoie alors 13 octets. Si on trace une ligne de 10 pixels, on devra envoyer 10 x (10bytes + 1+2 bytes) = 130 bytes. On perd un nombre important d'octets (9 x (10 bytes +1) = 99 bytes) et on pourrait imaginer d'envoyer 1 fois la position du curseur et ensuite envoyer l'ensemble des couleurs des 10 octets. C'est la technique de la pagination (voir chapitre suivant).
- Dû au boucle et à l’exécution du code, les octets ne sont pas envoyés rapidement. Nous perdons du temps entre chaque octet.
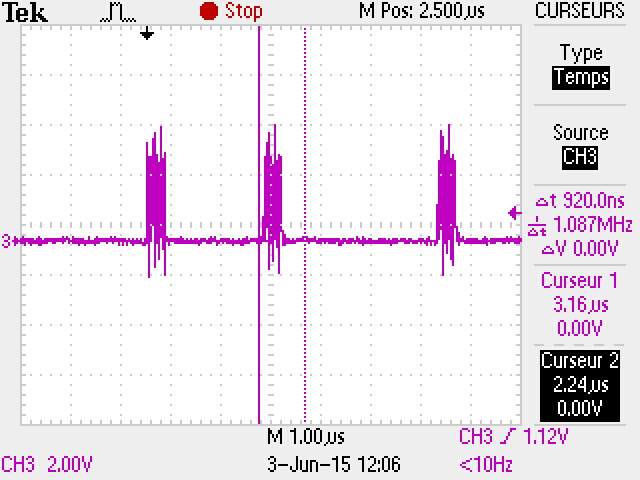
Au sujet du transfert SPI, regardez le graphique suivant :
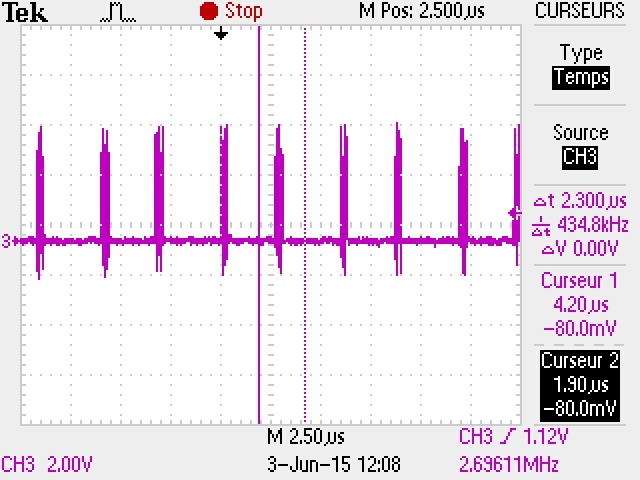
Pour une vitesse de 21Mhz sur la clock SPI, nous voyons que les octets sont envoyés en 400ns environ, mais il y a une période de 2.5us minimum (une valeur moyenne, avec mon code) d'inactivité de la clock et donc du transfert.
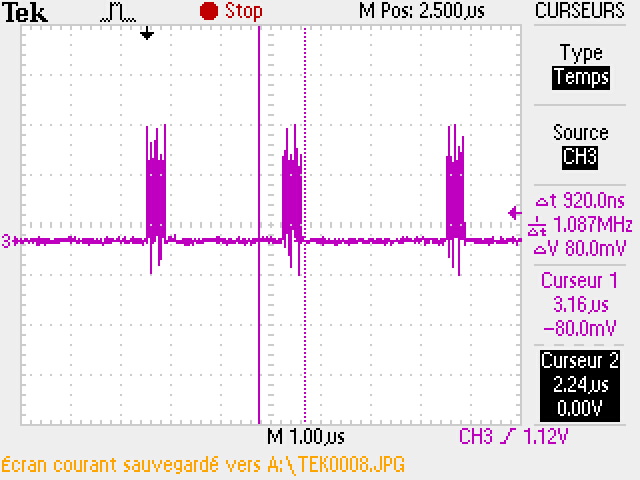
En faisant un calcul approximatif, on peut considérer qu'on peut gagner 2.5us / 400ns = 6 fois la vitesse actuelle si on ne perd pas de temps et qu'on envoie des octets dans la période d'inactivité.
Cette méthode fonctionne, mais n'est pas efficace. La méthode suivante améliore un peu le transfert mais pas dans des proportions énormes.
3- Librairie d'origine avec la méthode de pagination
Comme indiqué précédemment,la librairie d'origine de Tilen fixe toujours la position du curseur pour chaque pixel.
Pour une ligne, il n'est pas nécessaire dessiner pixel par pixel. Le ILI9341 offre la possibilité de définir une zone dans la GRAM pour laquelle on autorise le dessin. quand cette page est définie, on peut envoyer successivement chaque pixel sans repositionner le curseur. Le driver ILI9341 incrémente automatiquement la position lui même.
Donc pour une ligne, on a besoin de 10 octets pour la commande de fenêtre ( La fonction SetCursorPosition fait ça) et ensuite on envoie 1 octet de commande pour activer le mode GRAM. Puis on envoie tous les pixels en mode continu.
L'avantage de cette méthode est qu'on gagne 10 + 1 bytes par pixel.
Pour une ligne de 100 pixels, en couleur 16 bits,
sans pagination : le transfert coûte : 100 x (10 + 1 octet + 2 octets par couleur) = 1300 octets.
avec le mode pagination : Le transfert coûte : 10 + 1 octet + ( 2 octet par couleur x 100) = 211 octets.
Comme on peut le voir, le rapport théorique est de 5 à 6 fois plus rapide.
Pour optimiser la librairie, vous pouvez appliquer cette méthode pour putc, drawline, drawFillRectangle. Pour les autres fonctions, ce n'est pas nécessaire.
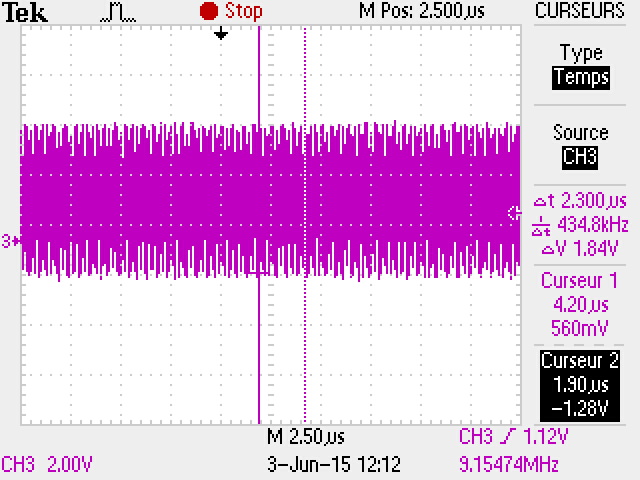
Si on applique cette méthode, on peut accélérer un peu la procédure d'affichage, mais ce n'est pas si efficace :
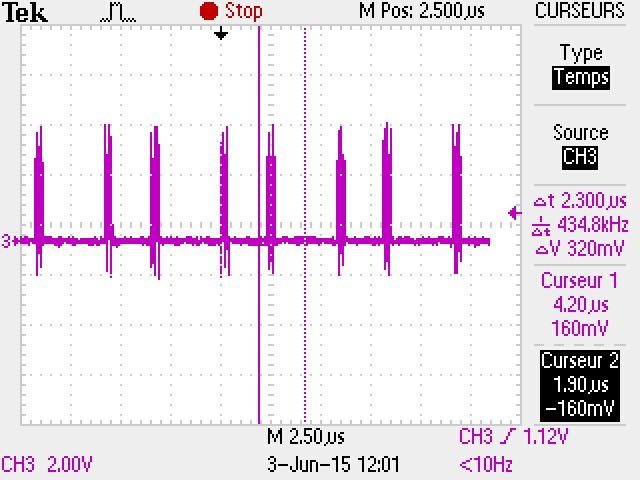
Vous pouvez voir que le transfert SPI est quasiment le même. c'est dû au fait que les pixels sont envoyés un par un, avec l’exécution du code de traitement entre chaque pixel (boucles, tests, etc..).
En pratique, on n'obtiens pas un gain de 5 à 6 fois. c'est beaucoup moins, et c'est dépendant du code que vous avez écrit. Vous pouvez voir dans la vidéo la différence entre les 2 méthodes.
La meilleure solution pour ne pas perdre du temps est d'utiliser le DMA pour le transfert.
4/ Librairie modifiée avec pagination et DMA.
Pour obtenir un transfert à pleine vitesse,il faut utiliser le DMA.
Le DMA est un système interne au STM32 (et sur beaucoup de composant) qui autorise le transfert de données entre mémoire/mémoire, mémoire/périphérique, périphérique/mémoire, périphérique/périphérique en automatique. Et ce, sans exécution de code.
Quand le DMA s'exécute, le coeur du STM32 peut exécute du code pour faire autre chose. Le DMA prend une donnée, l'écrit dans la destination, et recommence jusqu'à ce que le nombre de données spécifié ait été traité.
Par cette méthode, le transfert SPI se fait en mode continu. Il n'y a plus de période d'attente entre chaque octet pendant le transfert.
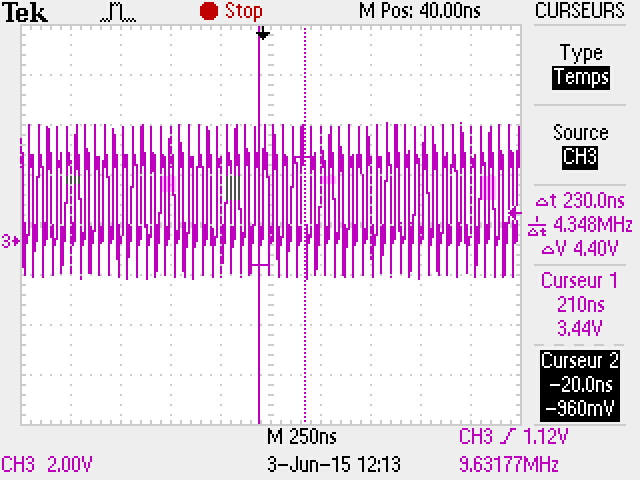
Avec un calcul rapide (le calcul n'est pas exacte, c'est just pour avoir une estimation des différences):
pour un rectangle de 10col x 20lignes avec la lib d'origine = 20 x (10 x (10+1 + 2)) = 2600 octets x 2.5us = 6.5ms
pour un rectangle de 10col x 20lines en pagination par ligne = 20 x (10+1 + 2( x 10)) = 620 octets x 2.5us = 1.55ms
pour un rectangle de 10col x 20lines en 1 page = 10 + 1 + (20 x 10 x 2) = 411 octets x 2.5us = 1ms
pour un rectangle de 10col x 20lines en page + DMA = 10+1 + 20 x 10 x 2 = 411 bytes x 400ns = 165us
Et pour vous donner des frissons, pour un rafraîchissement complet de l'écran:
pour un rectangle de 320 x 240 avec la lib d'origine = 240 x (320 x (10+1 + 2)) = 998400 octets x 2.5us = 2.5s
pour un rectangle de 320 x 240 en page par ligne = 240x (10+1 + 2( x 320)) = 155240 octets x 2.5us = 400ms
pour un rectangle de 320 x 240 en 1 page = 10 + 1 + (240x 320 x 2) = 153611 octets x 2.5us = 380ms
pour un rectangle de 320 x 240 en page + DMA = 10+1 + 240 x 320 x 2 = 411 octets x 400ns = 61ms
Ceci montre que le DMA est vraiment très utile pour le transfert de données en masse.
Si vous regardez ma vidéo plus haut, vous pourrez voir la différence sans et avec DMA. C'est impressionnant.
5- Remerciements
J'aimerai remercié :
Tilen de stm32f4-discovery.com pour sa librairie et pour son accessibilité lors des discussion sur le principe de traitement
Electrodacus, de la liste de discussion, pour ces indications et pistes de réflexion
BeNj, pour son aide sur FreeRtos et l’écran qu'il m'a prêté (que j'ai cramé, soit dit en passant ;-) )
J'espère que cette explication vous aidera a mieux comprendre l’intérêt du DMA pour le transfert de données en masse et spécialement pour le ILI9341.
6- Liens
- stm32f4-discovery.com de Tilen
- The page de discussion de la librairie d'origine